テキストエディタ開発の参考にしたもの
ライフワークとして、炊紙というテキストエディタを開発している。一般的なテキストエディタよりちょっと風変わりで、三次元空間上でテキストを編集するユーザーインタフェイスの価値検証が主な目的のテキストエディタだ。
なぜ、そんなものを作ろうとしているのか、その目的や情熱の詳細については GitHub のリポジトリの README.md に書き残したり Findy Engineer Lab にインタビュー記事にしてもらったのでそちらを参照してもらえばと思います。
このブログ記事ではインタビューの公開に合わせた補足として、炊紙というテキストエディタ開発のなかで参考にした面白いネットの記事を感謝とともに列挙していこうと思います。私の開発しているテキストエディタにはとくに感じるものがなかった人でも、これらのリソースは非常に面白いと感じるかもしれません。
シンパシーを感じるテキストエディタ
三次元空間で文章を編集するテキストエディタというのは、世の中にあまりない。私が単に見つけられていないだけという説もあるので、あれば教えてほしいというのが正直なところだ。ここに上げるテキストエディタはそれなりに類似点やシンパシーがあるため紹介したい。
- Bloom Editor
- 2011年に発表されたコンセプトムービーだけが残っているエディタ。非常にオシャレで 3D テキストエディタというコンセプトが自分の考えるエディタに近い。継続的なリリース、シェア獲得に至らなかったのが残念でならない。
- www.youtube.com
- Dramatic EDitor / GriddyCode
- どちらも GPU で文字をレンダリングしている最近のテキストエディタ。炊紙の開発開始時にはなかったようだが、最近改めて調べていたら見つけた。どちらも技術的に近いところにありそうなので切磋琢磨して頑張っていきたい。
- github.com
- github.com
- Zed
- Neovide
- stone
- Mac/iPad 専用のテキストエディタ。多機能にせず、文章を気持ちよく書くことに特化していることにシンパシーがある。縦書き・横書きのどちらにも対応している点もポイントが高い。日本デザインセンターという会社が有償でこのような思想の強いテキストエディタを販売しているという事実も、なんだか心強い気持ちにさせられる。文章を書くというのは思想の強いものなんだ!
- stone-type.jp
役に立ったアルゴリズムや技術記事
- Easy Scalable Text Rendering on the GPU
- gl2d-sandbox
- KOBA789 氏による上記ブログの OpenGL 実装。GPU でフォントレンダリングするのは自分の技術力では難しそうなので諦め気分もあったのだが、日本の人がシュッとやっていたので「俺もやったらぁ!」という気持ちにさせてもらえた。
- github.com
- Coding Adventure: Rendering Text
- GPU でフォントをレンダリングする動画。2024年公開。この動画がテキストエディタ開発当初のあの頃にあれば…。
- www.youtube.com
- Slug Font Rendering Library
- GPU でフォントをレンダリングするためのライブラリ。float の精度都合でフォントの描画が乱れる問題を完全に解決している(らしい)。レンダリング品質で目指すべき上はまだあるという気持ちになる一方、グリフ情報をテクスチャに書きだす必要があったり、論文を見る限りフラグメントシェーダーで for ループを回しているためパフォーマンス的なインパクトが気になる。
- sluglibrary.com
- 縦書きエディタを6プラットフォームで開発してみて
- 縦書きエディタ、TATEditor を開発されている方のこれまでの歩みを紹介したスライド。複数プラットフォームで縦書きエディタを追及されているすごい方。このスライドにある問題は大体自分も同じように悩んだのでとても共感を感じる。
- speakerdeck.com
- Learn Wgpu
- 最高の wgpu 学習用の教材。炊紙は当初 Java & JOGL で開発されていたが JOGL の開発が滞るのを機に Rust & Piston への移行を経て最終的に Rust & WebGPU(wgpu) になった。OpenGL に限界を感じてはいたものの C++ & Vulkan は自分の取る選択肢ではないと考えていた当時の自分にぴったりの選択肢と学習リソースが出てきたことは幸運だった。
- sotrh.github.io
- Easing関数
- テキストを滑らかに動かすにはイージング関数が必須という事は常々考えていたが、代表的なイージング関数と詳細についてはあまり把握していなかったのでこのサイトが非常に役立った。
- easings.net
- 三次ベジエ → 二次ベジエ変換
(おまけ) Hacker News 掲載
Findy さんにインタビュー記事を書いてもらえることになったのでそれに合わせて炊紙の公開準備をしていたところ、親切な方に Hacker News に GitHub リポジトリをタレコミいただき、炊紙の GitHub のスター数が一気に 3 ぐらいから 280 まで激増しました。ここでは印象に残ったやり取りを残しておきます。
Hacker News に宣伝すると星が沢山つくという噂は以前から聞いていたが本当に伸びた。すごい。登り龍だ。

- Emacs vs Vi
- 炊紙ではemacsキーバインドを採用しているが、無用な争いを避けるために README.md に「これは私の好みにすぎない」と書いたところ延々とエディタ争いのツリーができてしまった。俺のテキストエディタのトピックでエディタ戦争をしないでくれ。戦争より感想をたのむ。
- news.ycombinator.com
- 日本語障壁のおかげでスパム Pull Request から守られている
- 縦書きを大事にしたテキストエディタを作る時点で日本語圏以外を気にしても仕方がないなという気持ちになり、 UI 、コメント、コミットログ、README.md を全て日本語で書くことにしたが、そのおかげでこのリポジトリはスパムから守られているという謎の評価があった。日本では特に話題にならずに海外で盛り上がっているのを見ると英語で書いおいてもよかったかなという気も。プロジェクト運営の話より感想を頼む。
- news.ycombinator.com
- 新しい UI を期待している
- Hacker News 掲載は、正直ほとんどの人がまともにテキストエディタを評価してはくれず参考になったり励みになる書き込みはほとんどなかったが、一人だけコンセプトを理解してコメントをしてくれた人がいたのでうれしかった。海外の人が、日本語リソースとアニメーションGIFだけでここまで汲み取ってくれるとは思わなかった。
- (コメントの大意)「本来であれば VR/AR 空間上でコンピュータと対話するための新しい UI の再考は Apple Vision や Meta Quest などで行われるべきだったが行われなかった。iMac → iPhone のような新しい UI 標準の変化の取り組みが起きていないことは残念だ。しかし(炊紙のような)オープンソースプロジェクトが UI について新しい可能性を示してくれることを期待している。」
- news.ycombinator.com
まだまだ完成には遠いですが、この炊紙は盆栽としてのポテンシャルは高く、個人の盆栽プロジェクトを作るのは自分の憧れの目標でもあったため今後が楽しみです。
以上。
ビルド結果に影響を与えるファイルを突き止めろ!
ソースコードをリポジトリからチェックアウトしてビルドする際に
「このビルドを実行する時、どのファイルが参照され成果物に影響するだろうか?」
と考えたことはありますか?
「このディレクトリの変更だけ監視してCIを走らせればオッケーです」
「このコミットは本番の成果物に影響を与えないのでテスト不要です」
本当でしょうか?
私たちはビルド結果に影響を与えうるファイル群を真に把握できているでしょうか?
ソフトウェア開発は人間の認知の限界を軽々と突破します。知らない間に想像していなかった依存がどんどん入り込んできます。
なので、私はツールなどの補助なしに人力では把握しきれないと考えています。
きっと GitHub Actions の paths-filter を漏れなく書くのは大変な仕事に違いありません。
Summary
という事でこの記事の三行まとめです。
- ビルド時に使われるファイルは少なくともビルド時に参照が行われるだろう(仮説)
- ビルド実行時に inotify などを用いれば参照されたファイルをリストアップすることができる(linux only)
- sver というコマンドにリストアップのためのコマンド
sver inspectを実験的に実装したよ
使い方など
Summary を書いたらこれ以上説明することも無くなってしまったので sver inspect というサブコマンドの使い方を書きます。
sver そのものの説明は 同じビルドやテストを何度も実行しない方法 というブログ記事を以前書きましたのでそちらを参照ください。
sver inspect はあるコマンドを実行する際にカレントディレクトリが所属する git リポジトリに inotify の watcher を仕掛け、コマンドの実行が終わった後にアクセスされたファイルをリストアップします。
コマンドの凡例は以下のような形式です。
sver inspect [OPTIONS] <COMMAND> [ARGS]...
例として cargo fmt --all を実行するときに参照されたファイルをリストアップする場合は以下のようになります。
sver inspect -- cargo fmt --all
-- はオプション形式の引数が sver コマンドに解釈されないための区切りです。-- 以降の引数はすべて COMMAND (この例では cargo )に渡されます。
実際に実行してみると以下のような出力になります。src だけでなく tests も参照されていることがわかります。
$ sver inspect -- cargo fmt --all Cargo.toml src/cli/args.rs src/cli/mod.rs src/cli/outputs.rs src/filemode.rs src/inspect.rs src/lib.rs src/main.rs src/sver_config.rs src/sver_repository.rs tests/integration_test.rs tests/test_tool.rs
このように、あるコマンドを実行したときにどのファイルが参照されるかをツールでリストアップすることで、想定していなかったビルドコマンドの依存も確実に検出することができるかと思います。
以上、今回実装したサブコマンドが皆さんの快適な依存関係把握ライフにつながれば幸いです。
同じビルドやテストを何度も実行しないための GitHub Actions
前回 同じビルドやテストを何度も実行しない方法 として GitHub Actions での実現方法や sver というコマンドラインツールを紹介しました。
今回、汎用的に使える部分を sver-actions として切り出したので紹介します。
内部動作の詳細については 同じビルドやテストを何度も実行しない方法 で書かれたもののままです。仕組みが気になる方は前回の記事を参照ください。
使い方
sver-actions は 2 つの Action に分かれています。
一つは sver をセットアップするための mitoma/sver-actions/setup@v1。
もう一つは sver を使ってあるバージョンのジョブの実行が一度成功すれば次回からスキップする mitoma/sver-actions/exec@v1 です。
Setup action
セットアップするアクションは簡単です。 典型的には step に以下のように書いておけばこのステップ以降 sver を使ってバージョン計算をすることができます。 デフォルトでは linux にその時の最新バージョンの sver をインストールし、パスを通します。
- uses: mitoma/sver-actions/setup@v1
linux 以外の OS を使いたかったり、特定のバージョンをインストールしたいときには以下のように指定できます。
- uses: mitoma/sver-actions/setup@v1 with: # linux, windows, macos のいずれかを指定することができます os: windows # お好きなバージョンをインストールすることができます version: v0.1.14
Exec action
実行するアクションは少し設定が必要です。
このアクションを実行する前に mitoma/sver-actions/setup@v1 で sver をインストールしておく必要があります。
実行したい内容 command と、その結果実行結果を GitHub Actions の artifact に保存するために phase と github_token を渡す必要があります。
設定例を示します。
- uses: mitoma/sver-actions/exec@v1 with: phase: build github_token: ${{ secrets.GITHUB_TOKEN }} command: | cargo build
上記のように指定すると初回のジョブでは cargo build を実行し、成功すれば {phase}-{version}.success 形式の 0 バイトのファイルを artifact としてアップロードします。例でいうと build-18b280c304ab.success といった感じの名前になります。
そして初回以降、 {phase}-{version}.success という名前の一致する artifact が見つかる限りこのジョブはスキップされます。
ジョブを実行するかどうかをある特定のディレクトリ以下やファイル群の変更に限りたい場合には path を使ってバージョンの計算対象を変更することができます。ライブラリの依存関係やジョブの性質によって詳細に対象を制御したい場合には sver の sver.toml を記述して設定します。
また、ビルド時のキャッシュの利用やビルド結果を artifact にアップロードする処理もこのアクションで制御することができます。
以下は指定できるパラメータの設定例です。このパラメータの説明など詳細は sver-actions/exec を参照いただければと思います。
(基本的には内部で actions/cache/save, actions/cache/restore, actions/upload-artifact を呼び出しているだけです)
# standard rust project example. - uses: mitoma/sver-actions/exec@v1 with: # ビルドのフェイズ。リポジトリの CI の中で一意な名前をつける。 phase: build # ビルド時に artifact をアップロードするため、権限のある TOKEN を指定する必要がある。 github_token: ${{ secrets.GITHUB_TOKEN }} # ジョブのバージョンを計算対象とするパスを指定する。 path: . # 実行するジョブの内容を書く。複数行書いてもよい。 command: | cargo build --release # キャッシュを restore だけでなく save するときに true を指定する。デフォルト true。 # 例ではデフォルトブランチの時のみキャッシュを保存する。 cache_save_enable: ${{ github.ref == format('refs/heads/{0}', github.event.repository.default_branch) }} # `actions/cache/save` の `key` と同様。 cache_key: cargo-${{ hashFiles('**/Cargo.lock') }} # `actions/cache/save` の `restore-key` と同様。 cache_restore-keys: | cargo-${{ hashFiles('**/Cargo.lock') }} cargo- # `actions/cache/save` の `path` と同様。 cache_path: | ~/.cargo/registry ~/.cargo/git target # `actions/upload-artifact` の `name` と同様。ただし、末尾に `-{version}` が付与される。 artifact_name: build-result # `actions/upload-artifact` の `path` と同様。 artifact_path: path/to/artifact
以上、本アクションが皆さんの快適な CI ライフの一助となれば幸いです。
同じビルドやテストを何度も実行しない方法
GitHub Actions で同じビルドやテストを何度も実行しない方法を紹介します。
ホストランナーを ubuntu-linux にした場合、実行する必要のないジョブは 10 秒程度でスキップ可能です。
注意 この記事は自作の OSS ツール sver および私が現在所属するサイボウス社の グローバル向けAWS版kintone開発チーム の宣伝が含まれます。
Summary
- ビルドやテストといった CI のジョブに再現性がある場合は複数回実行しても意味がない
- ジョブが依存する環境やソースコードを元にハッシュ値を計算することで同等なジョブに一意なラベルをつけられる
- ジョブ実行後に実行済みラベルを artifact として保存しておくことで後続の同等なジョブをスキップできる
効果
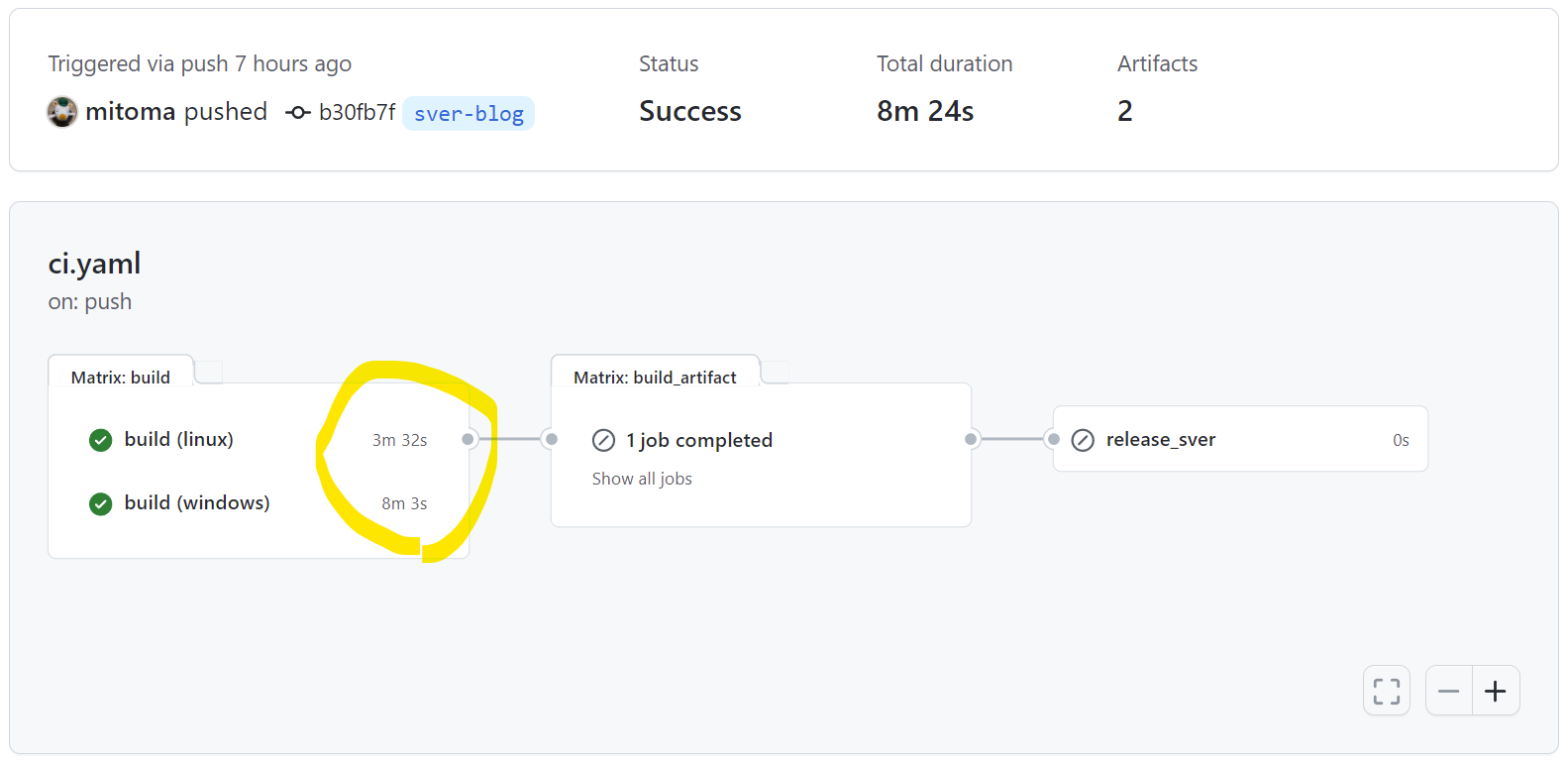
最初に効果を示します。 sver というプロジェクトのジョブの実行結果です。
これは通常時のジョブの実行時間です。ubuntu-latest で 3 分 32 秒。windows-latest で 8 分 3 秒かかっています。
毎回ナイーブに実行するには長いジョブだと感じていただけるかと思います。
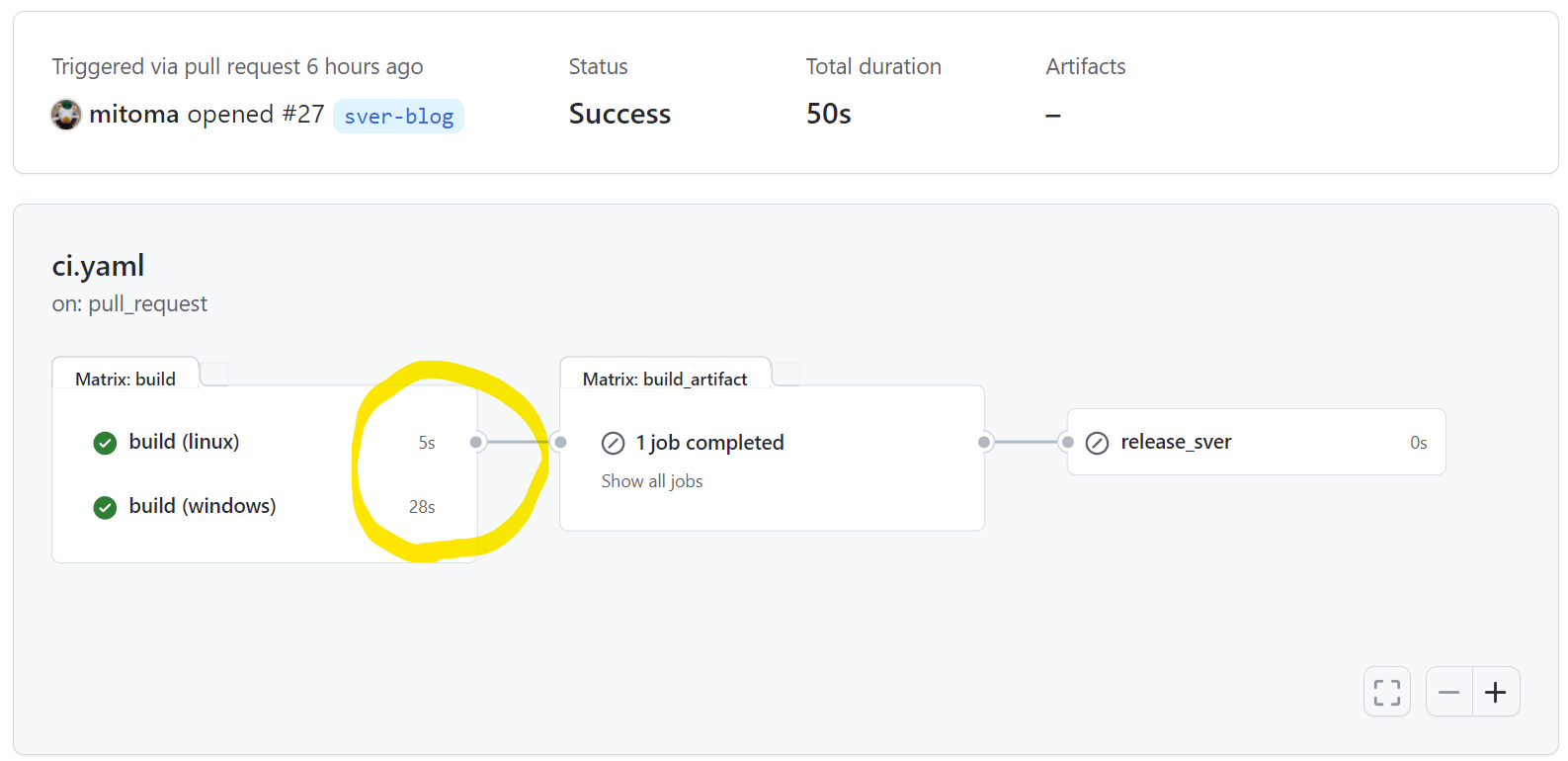
次はスキップ可能と判定されたジョブの実行時間です。ubuntu-latest で 5 秒。windows-latest で 28 秒かかっています。
どちらのホストランナーも立ち上げ時間とわずかな判定時間だけでスキップ判定してジョブを終了しています。
これでも多少の時間はかかってしまいますがナイーブに実行することと比較すると短い時間です。
この仕組みがどのように実現されるか見ていきましょう。
同じビルドやテストを何度も実行してしまう
開発時に CI/CD を行うことが一般的になった現代では push や pull req、タグ付けなど様々なイベント毎にビルドやテストを実行します。 また monorepo のように複数のサービスを 1 つのリポジトリにまとめるプラクティスの適用もマイクロサービスの興隆の状況下で増えてきています。
その結果、リポジトリ内のとある変更が CI の結果に影響を及ぼさないことが明らかな場合でも何度もビルドやテストを実行してしまうという状況が発生してしまいます。
これらはスローテスト問題や計算資源の大量消費という形であらわれ、時間と費用の両面で開発コストを押し上げます。
ビルドやテストが無駄になってしまう例としては、ある修正を入れて push → 間違いに気づき revert して push などがあります。この場合、修正を入れる前に CI が通っていたのならば revert 後に再度 CI を実行する必要はありません。

あるいは、リポジトリ上の README.md やドキュメントを編集したときにビルドやテストなどの CI が走っても無駄なことが多いでしょう。
事前にジョブの実行が無駄なのが明らかなケースでは [skip ci] などのコミットコメントで抑制することもできますが、ジョブが無駄かどうか自明なケースは限られています。
注釈 同じソースコードに対して複数回ジョブを流すことが無駄と言えるのはジョブに再現性がある場合です。
再現性があるとは、同じ入力(ソースコードや環境)であれば何度そのジョブを流しても同じ結果になるという事です。
外部のライブラリバージョン指定が曖昧であったり、FlakyTest がある場合は再現性に難があると言えるでしょう。
同じ入力に対して一意なラベルをつけよう
ジョブに再現性があるという前提の下では、過去のジョブの結果を保存しておけばそのジョブはスキップ可能です。
ですが、過去のジョブと現在のジョブは同じものかどのように照合すればよいでしょう。
これは、ジョブの入力に対して一意なラベルをつけることで照合可能です。
ジョブの入力とは、そのジョブで使われるソースコード一式とジョブが実行される環境です。
GitHub Actions などリポジトリにジョブの定義ファイルを配置するタイプの CI ツールであれば環境もソースコードとみなして扱うことができます。
注釈 GitHub Actions でホストランナーを runs-on: ubuntu-latest など指定した場合に環境が一意と呼べるかについては、求める一意性の厳密さ次第です。
ではジョブの入力に対して一意なラベルをつけるにはどのような方法があるでしょうか。

簡易的にはツリーオブジェクトのハッシュ値を用いる方法があります。git rev-parse HEAD^{tree} で計算可能です。
songmu さんの "同じソースツリーでテストが通っていたらテストをスキップする" というブログでも git コマンドと S3 を用いる方法が紹介されています。
この方法を用いると、ブランチ違いの同一ジョブ、push・pull-request といったイベント違いの同一ジョブの実行を抑制することができます。
ただし、ジョブの成果物に影響のない変更でもハッシュが変わってしまうため、ドキュメントをリポジトリに入れていたり、monorepo のように多数のサービスが含まれるリポジトリでは git rev-parse HEAD^{tree} でも十分ではありません。
厳密には echo <ジョブに使われるファイルのリスト> | xargs -I@ cat "@" | sha256sum のようにハッシュ値を計算することで、リビジョンやブランチに左右されないそのジョブ固有の値が得られるでしょう。
しかし <ジョブに使われるファイルのリスト> を洗い出してハッシュ値を計算するのは面倒です。
ハッシュ値計算を簡略化する方法についてはそれ専用のツール sver を後述します。
実行結果のラベルを artifact として保存しよう
ラベルを作るためのハッシュ値さえ得られればあとは簡単です。
ジョブが成功したかどうかを表すラベル名を <ジョブの種別>-<ジョブ固有のハッシュ値>.success とでも定義します。
そして、ジョブの実行開始時に GitHub Actions の artifact としてラベル名のファイルが存在するかを確認します。そしてファイルがあれば処理をスキップし、無ければ処理を継続して成功すれば artifact としてファイルを保存します。ラベル名に意味があるので、ファイルサイズは 0 でかまいません。
過去の artifact の参照して成否を判定するには gh コマンドを用いるのが簡単でよいでしょう。
exit_code=0 gh run download -n '<ジョブの種別>-<ジョブ固有のハッシュ値>.success' || exit_code=$? echo "##[set-output name=exit_code;]${exit_code}"
GitHub Actions では artifact の保存期限は最長 90 日なので、それ以上過去に実行されたケースではジョブが再実行されてしまいます。要件的に再実行を許容することが難しければ保存期限が自分でコントロールできる S3 や DynamoDB といった外部のストレージの利用を検討するとよさそうです。
この方法の良いところ、悪いところ
この方法は「大規模で効率的なビルドをするなら Bazel が良いかもしれない。
けれど Bazel を採用するには大げさかもしれない。しかしビルドやテストを毎回行いたくない…」
という要求が発端で生まれました。
やっていることはあるファイル群から一意なハッシュ値を計算するだけです。
この方法を採用するとき Bazel などの monorepo 専用のビルドツールを使う場合に比べて以下のメリット・デメリットがあるでしょう。
メリット
- 既存の言語毎のデファクトスタンダードとなるビルドツールをそのまま使い続けられる
- ハッシュ値を何に活用するかは自分たちの要件で決められる
デメリット
- モジュール間の依存関係をビルドツールなどの機能とは別に独立して管理してやる必要がある
- ハッシュ値計算、キャッシュ、スキップの戦略などの作りこみをすべて自分たちで検討する必要がある
一般的にビルドツールや CI/CD 周りの仕組みは「そういうのが好きな開発者」以外はあまり手を付けないものです。
そのような状況下で monorepo 特有の課題を解決するような専門のビルドツールを持ち込むと様々な問題が出てきます。
それは例えば以下のようなものです。
- 検索しても知見が集まらない
- monorepo は世間で広く採用されているわけではないので知見が少ない
- 世の中のスタンダードにうまく乗れない
- 世の中のスタンダードは小さなリポジトリを前提としていることが多い
- 自分たちの要件にうまくマッチしない時に乗り換えにくい
- monorepo 特有のツールは大掛かりになりがちで、導入も廃止もコストが大きくなる
一方で、この記事で提案するようにシンプルな方法で開発体験を損なわないようにメンテナンスしていくというというのも同様に簡単なものではありません。
しかし、世のスタンダードに乗りやすい & 自分達の要件に合わせやすいというのは大きな利点です。
この記事がお読みいただいた方のプロダクトの CI/CD 戦略を決める一助になれば幸いです。
[PR] 私の所属するサイボウズ社のグローバル向けAWS版kintone開発チームでの事例を元にしています。
私たちはこの方法で最適化されたリポジトリを 3 年以上運用しています。
採用情報はこちら
ジョブに使うソースコードからハッシュ値を計算するツール
さて、ここからはコードリポジトリのハッシュ値を計算するツールの紹介です。
このツールを紹介するためにはそのモチベーションを説明しなければならないので前置きが長くなってしまいました。
git コマンドによる解決の課題
同じ入力に対して一意なラベルをつけよう では <ビルドに使われるファイルのリスト> からハッシュ値を計算するとよいと書きました。しかし、ファイルのリストを手動で定義し、開発プロセスの中でメンテナンスしていくのは現実的ではありません。
例えば以下のような monorepo があるとしましょう。
. ├── README.md ├── doc │ ├── Design.md │ └── Roadmap.md ├── libs │ ├── lib1 │ └── lib2 └── services ├── service1 └── service2
例えば services/service1 のサービスからハッシュ値を計算するにはどうすればいいでしょう。
簡単に対応するのであれば以下で済むはずです。
cd services/service1 git ls-files | xargs -I@ cat "@" | sha256sum
しかし services/service1 が libs/lib2 に依存していたらどうでしょう?
libs/lib2 以下のファイルも依存に含める必要があります。
また、あるタイミングから libs/lib2 が libs/lib1 に依存するようになったらどうでしょう?
libs/lib1 以下のファイルも依存に含める必要がありますが services/service1 の依存ファイルをメンテするときに漏れずに対応できるでしょうか?

ハッシュ値計算ツール sver
このようなハッシュ値計算の問題を解決するためのツールが sver です。
サイボウズ社の グローバル向けAWS版kintone開発チーム の社内ツールで使われているアイデアを元に個人の OSS として開発されています。
注釈 社内ツールは Bazel の BUILD ファイルを参考にしているので、これはその孫引きと捉える事も出来るでしょう。
sver は小さな rust 製のコマンドラインツールで git リポジトリのファイルのハッシュ値を計算できます。
「ソースコードから一意なバージョンを作る」という意味を込めて "Source VERsion" → "sver" としています。
発音は決めてませんが「えすばー」と呼んでます。
例えば、先ほどの services/service1 のハッシュ値を計算するコマンドは以下のようになります。
$ sver calc services/service1
ef5d3d3db6d5 # ← 算出されたハッシュ値
services/service1 が別のディレクトリに依存しているときには sver.toml という設定ファイルを services/service1 以下に配置してやることで推移的にファイルのリストを追加できます。
[default]
dependencies = [
"libs/lib2"
]
excludes = []
あるタイミングで libs/lib2 が libs/lib1 に依存を追加することになったときには libs/lib2 に以下の sver.toml を配置してやるだけで sver calc service/service1 は推移的に libs/lib2 と libs/lib1 のファイルもハッシュ計算に用います。
[default]
dependencies = [
"libs/lib1"
]
excludes = []
実際にリポジトリ中のどのファイルをハッシュ計算に用いているか確認したくなった時は以下のコマンドでリストすることができます。
$ sver list services/service1 libs/lib1/xxx.rs libs/lib1/yyy.rs libs/lib2/zzz.rs testdata/service1/main.rs ...
他にも以下の機能/特徴があります
- ファイル実行権限、シンボリックリンク、submodule を考慮したハッシュ計算
- 依存ディレクトリ/ファイルの指定、除外ディレクトリ/ファイルの指定
- sver.toml が循環参照が含む場合も解決可能
- リポジトリ内の
sver.tomlに矛盾がないかどうかの検証
このコマンドを用いることでリポジトリ内に複雑な依存関係を持つケースのハッシュ計算が簡単にできます。
適用例
- GitHub Actions で sver コマンドをインストールするには setup_sver/action.yaml が参考になります。
- sver を用いて artifacts があるときにはジョブをスキップする処理の作りこみには exec_sver/action.yaml が参考になります。
- 上記二つのカスタムアクションを利用した実際の適用例は ci.yaml になります。
詳細や現在の開発状況についてはリポジトリ https://github.com/mitoma/sver をご参照ください。
Altanative
sver や Bazel 以外の monorepo の課題を解決するためのツールについては monorepo.tools や awesome-monorepo などを参照するとよいでしょう。
最後に
ビルド時間の削減はあなたの開発者生活を豊かにしてくれます。
ビルド待ち時間のちょっとしたコーヒーブレイクや、仕方なく行われる twitter での長時間の情報収集時間は失われてしまうかもしれませんがそれは些細なことです。
その代わり、勤務時間後のカフェタイムや、週末にとてもクールな tweet をするための活力が手に入る事でしょう。
システムの利用者に安全に独自のビジネスロジックを定義させる
SaaS の活用が日々盛んになってきている昨今。皆様精力的に SaaS システムを開発されていますでしょうか。
私は最近、子供とScratch3.0でゲームを作ったりしています。
マルチテナントシステムが利用者の個別要件を受け入れるためには
さて、マルチテナントシステムを提供する際の困難な仕事の1つは
- 「うちがこの製品を利用するにはこの機能が必要だ」
- 「ここにこのようなビジネスロジックを入れることができなければ使い物にならないね」
といった個別の要件を「この要件は全顧客に提供すべきだね」と取り入れながら「これを必要とするのは御社だけですね…」と払い除けることです。
しかしながら、そのような要求を声に出すお客様というのはやはりとても重要なお客様であることが多いので無碍にすることはできません。
またそのような要求を持ちつつ、追加開発を要求する予算や権限が無いというお客様も当然多いです。サービスベンダとしては提供するシステムを末永く活用していただくためにはお客様の個別の要求にも応えられる仕組みを備える必要があります。
実現方式
さて、ではそのような顧客の個別要件を受け容れるためにはどのようなやり方があるでしょうか。
ぱっと思いつくのは上記のようなものでしょうか。ざっくり検討していきましょう。
サービスベンダで開発
一番古典的です。サービスベンダが顧客の要求からカスタマイズを開発し、提供するシステムそのものに組み込みます。該当御客のときのみ機能フラグでその機能が動作するようにします。ソースコード中に「// ○○社様向けフラグ」みたいなのが入るわけですね。
これは(正しくハンドリングすれば)お金は大きくいただけますが、システムが抱える依存関係・負債も大きくなります。開発者が辛いだけでなく、システムの健全な成長を妨げる事が多いです。「○○社様向けカスタマイズの機能があるので、これを考慮すると新機能Xが入れられない」というわけです。また、システム本体に手を加えるため多くの会社のカスタマイズ要望に応えきれません。
APIやSDKの提供
現代的です。システムの拡張ポイントとしてREST APIやそれを呼び出す言語用のSDKなどを提供することでシステムをカスタマイズします。これにより、開発がサービスベンダのシステムの主担当チームだけでなく、他部署や他社のSIer、開発力のあるユーザー自身が行うことができるようになります。
これにより、開発者は公開したAPIやSDKをメンテナンスするだけでよくなります。また、個別の開発をスケールさせることができるので多くの顧客の要望に答えることができます。ただし、開発がスケールする代償として個々のカスタマイズの品質のコントロールが困難になり想定を超えた(異常な使い方をする)ユーザーが登場します。適切なリミッターやスロットリングをするだけでなく、カスタマイズ開発者の教育や開発体験の向上などに継続的に取り組んでいく必要があります。
独自DSLやその実行環境の提供
こちらも現代的です。システムそのものに独自のDSLを組み込みユーザー自身がカスタマイズを作成します。「カスタマイズできる」というよりも「もともと自由度の高いメタなシステム」という見え方になるかもしれません。 Salesforce では Apex などが提供されていますし、最近では low-code/no-code(LCNC) development platform と呼ばれるものもこれに当たると考えています。
システム利用者の裾野の広がりに伴って、システム利用者のうち開発力のあるユーザーの割合が無視できない規模になっているという市場の変化によって、ユーザー自身が手軽かつ安全に開発を行えるようにすることでカスタマイズの開発を更にスケールさせるという戦略が取れるようになってきたと言えそうです。
ただし、カスタマイズの自由度は独自DSLやその実行環境が提供する語彙・機能に限定されますし。これは、利用者側に謎な行いをさせないという点ではメリットになりますが、システム開発者は一段メタな機能の開発に携わることになるため機能要件・非機能要件の策定に苦しむことになるでしょう。
どうでしょう
私個人としては以下のような評価をしています。
やってみましょう
サイボウズ株式会社の kintone というサービスをベースに「独自DSLやその実行環境の提供」のプロトタイプを作ってみましょう。
できたプロトタイプが以下です。Chrome 拡張として実装していますので kintone ユーザーの方はお試し可能です。

説明
kintone ではアプリと呼ばれる RDBMS におけるテーブルのようなものを画面から定義することができ、それを用いて日常業務をなんだかいい感じにすすめることができます。詳しいことは こちら(kintoneの公式サイト)。
kintone では「APIやSDKの提供」によってシステムの機能を超えるカスタマイズの要求に応えています。
今回紹介したプロトタイプではBlocklyでラップする形で独自DSLやその実行環境および開発環境を作ってみました。
Blockly
Blockly とは Google が開発したビジュアルプログラミング環境を作成するためのライブラリで、その名の通りブロックを組み立てるようにプログラミングをすることができます。冒頭で出てきたScratch3.0でもそのコアとして採用されていますし、Microsoft Makecodeやプログルを始めとした多くの教育系プログラミングのサービスで利用されています。
Blockly は根本的にはプログラマから見ると AST エディタでしかなく、そこで構築した AST から任意の言語のコードや実行環境の呼び出しをすることでプログラムを実行します。ブロックを積むように AST を構築しているだけと考えると、多くの人が「括弧を並べて AST を構築してるだけの、自由奔放な言語があったような…」と思いを馳せる事があるかもしれませんがそれは別の話。
しかしながら、これから数年後の世代の人間はブロックプログラミングに触れた経験がある状態で社会人になる方が多数になる可能性があるので、システムのビジネスロジック定義にブロックプログラミングを導入するのは悪くない選択かもしれません。
この記事の目的
途中から話がおかしくなってきたことにお気づきかもしれませんが、この記事の目的はせっかく作った Chrome 拡張のユーザーが居ないので宣伝がしたかったということに尽きます。
kintone ユーザーの皆様や、興味を持った開発者の皆様はためしに使ってみてください。kintone アカウントがなくても開発用途であれば開発者ライセンスというものがあります。
それはさておき
マルチテナントシステムの設計やブロックプログラミングの活用などなど、夢があり楽しいことを日々やっていきましょう!
プログラマとミールキット
男子厨房に入らず。そんな時代はとうに過ぎた現代。しかし我が家のキッチンは依然妻の独壇場となっていた。
手伝いをしようにも男子大学生自炊飯(必修)しか履修していない我が身では土曜に餃子を包んだり、焼きそば、たこ焼き程度が貢献できる限界であった。
特段育児が得意でない夫婦なので子供二人を相手するだけでも日々の疲労は常にマックス状態。この状態で毎日の献立を考え調理するのは高コストであり、担当者一人でこの作業を続けるのはとうてい持続可能な生活と呼べるものではなかった。
というわけで一つの決断をした。「我々は献立を考えたりそれに合わせて食材を適量調達する事を放棄する。マニュアル通りに食事を作る作業者で構わない」
多くの職場では「あなたはただの作業者で居てはいけない。常に新しいアイデアで現場を楽しみ、より良くしていこう」というような事を言われるだろう。だけど我々はより自由であるはずの家庭で、創造性を発揮する事をやめて作業者になることに救いを求めた。
仰々しく書いたがなんのことはない、ミールキットと呼ばれる献立の手順書と人数分の食材を定期注文して夕食作りで楽しようとした話である。
「毎日食事作るの大変そうだしミールキットで手順通り作る食事でよければ自分も手伝えるかも」みたいな雑な提案だったのだけど、意外とすんなりOKが出た。
なので、我々は特に考えもなしにヨシケイとオイシックスの二つをお試しで注文した。いまでだいたい一か月ぐらい続いている。どちらをメインにするかはまだ決めかねている。
↑と、ここまで下書きで書いた後にさらに二か月ほどたった。個人的にはヨシケイがよかったが妻的にはオイシックス希望だったのでそっちになった。
わかったこと
- 素朴な献立でいくならヨシケイ。現代的な味を求めるならオイシックス
- 宅急便のオイシックスよりも玄関前においてくれるヨシケイのほうが受け取りは楽
- とにかく何も考えなくてもいいのはストレスフリー
- おそらく栄養士がこれなら標準的と考える一人前の料理の分量がわかる
- 栄養にバランスも自分で作るよりも良いような気がするので偏りを何も気にしなくてよい
- 意外と料理に使われる野菜の分量はちょっとだという知見(玉ねぎ1/4とか人参1/3とか)
- 誰でも同じメニューが作れるので手が空いている方が作れば済む
- 更に手順書があるので作業途中の引き継ぎが容易
- 時短レシピなのもあるだろうけど「家庭料理なんてこの程度雑でも成立する」という事が実感できる
- 何を作ったって子供は期待通りには食べてくれない
意外だったこと
- いちょう切りとか小口切りとか謎の専門用語が出てくる。いや、小学校の時の家庭科で習った気はするんだけども覚えてないよ…。
- 家に当然あるべき調味料、みたいなもののレベルが意外と高い(特にヨシケイ)
結論的なこと
便利。こういうミールキットに以前は割高で非効率ではないかというよくわからない抵抗感があったのだけど、「金の弾丸で家事を効率化する」と表現されるもの、いわゆるルンバ的なものと同じカテゴリで考えるとその価値がよくわかる。特に子供がいるなど安定的な生活を回すことが重要な人たちにとって助かるものだと思う。
この記事は結局ミールキットを試してみた所感であって別にタイトルで書いたプログラマであることは特に重要ではない。
以上。
チームのやっていきを言葉にする
先日 ovento というイベントで対外発表をしてきた。
Osaka Venture Today Meetup という freee さんの主催するイベントで、技術的に良い話をしながら参加企業が良いエンジニアと出会って良いことが起きればいいなという感じの会。
自分は今やっているプロジェクトで「コンシューマ駆動契約」というテスト手法のひとつを紹介した。マイクロサービス時代に、どうやってサービス間で動作を保証しながらも独立した素早いリリースサイクルを実現するかという、わりかし新し目の要求に対する一つの解となるものだ。
小さなサービスも契約する時代 from RyoMitoma
www.slideshare.net
詳細は資料を読んでもらえばと思うので、特に説明はしません。
他人のふんどし
自分はわりとスライドやブログでプロジェクトのアーキテクチャや技術的なポイントを説明する上記のような資料を書くのが好きなので「我々がやっているのはこういう目的意識で〜こういう構造を目指して〜ここが面白くて〜」みたいなことを自分の理解の整理も兼ねて書いている。
しかし、プログラマ人生も長くなってきたせいか自分は会社においてはすでに「やっていきプログラマ」としては引退気味である。
「チームのやっていき >>> 自分のやっていき」みたいな状況で資料をまとめたりしていると「こういう行いは他人のふんどしで自己のビジビリティを高めるズルい行いなのではないか〜」とか「自分自身のコンテンツやプロダクトを生み出して世に問いかけるべく精進すべきでは〜」みたいな謎の葛藤がしばしば発生する。
「チームのやっていきを言葉にする」というのはそういう葛藤の中でふと思いついたフレーズだけど、こう表現すると他人のふんどしよりは自分のやっていることをもう少し前向きに捉えられる。
やっていく人間の中にはすでにチームで十分共有された事を改めてまとめるよりも、よりやっていくことを大事にする人が多く、しばしば外部からは何をやっているかが全く見えないという状況が発生する。
だから自分はチームのやっていきを言葉にして、チームの姿が周囲からよくわかる助けになれば、それは自分が中心となって進めたことでなかったとしてもそれで良いことなんだろう。
いい話につなげようとしたけどなかなか難しいので、ただの日記でフィニッシュです。